
We use cookies to improve browsing on our site. Review our Cookie Policy to learn more.
Extract superior insights from your data and
develop state-of-the-art AI solutions
Our AI-powered data generation platform enables data analysts and machine
learning engineers to maximize the value of their analytical data sets. By
leveraging the behavior extracted from existing data, Datomize enables users
to generate the exact analytical data sets needed. Equipped with data that
comprehensively represent real-world scenarios, users can now gain a far
more accurate reflection of reality and make much better decisions.
Replicate and resize your data
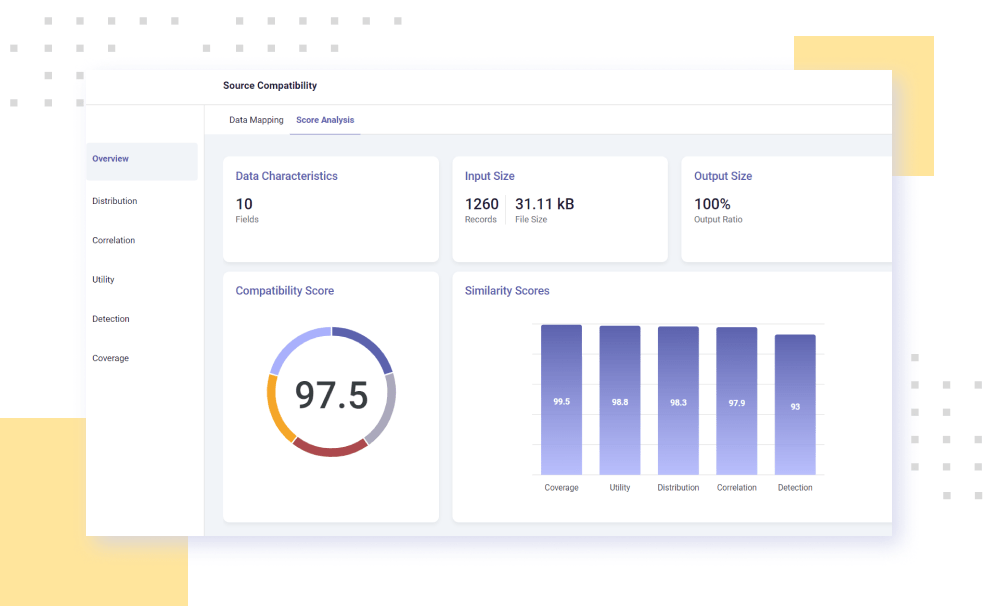
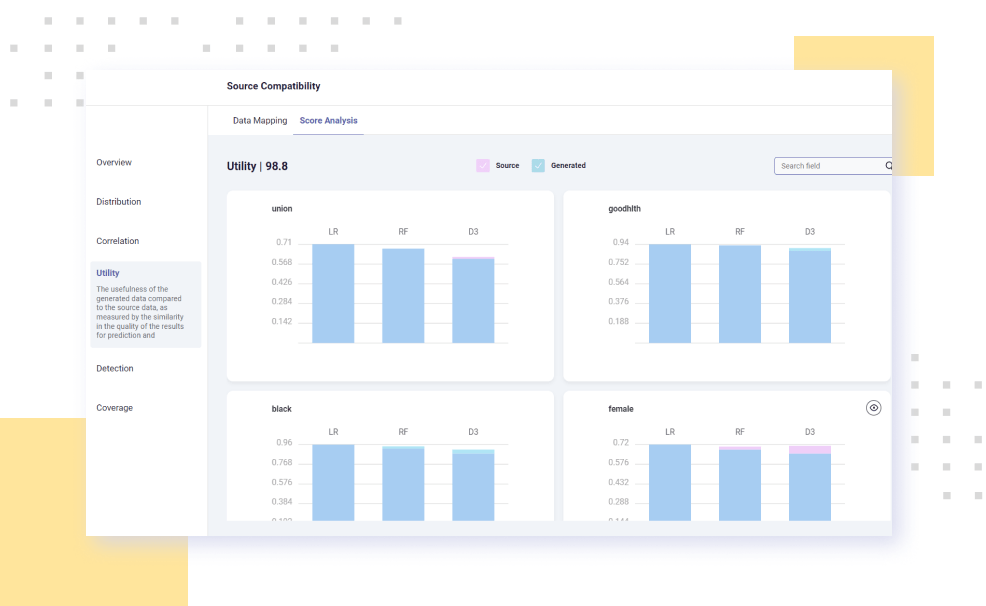
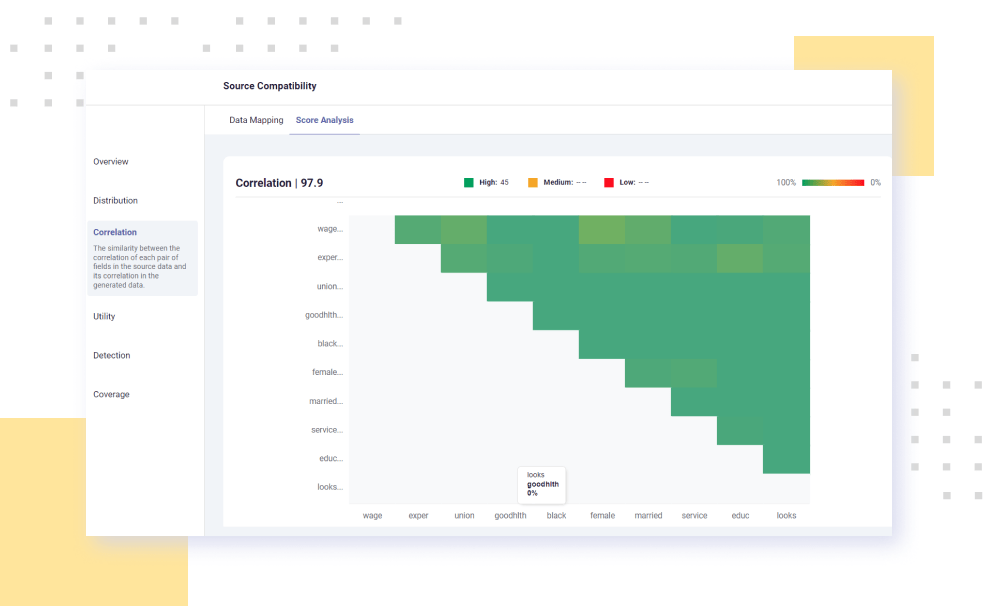
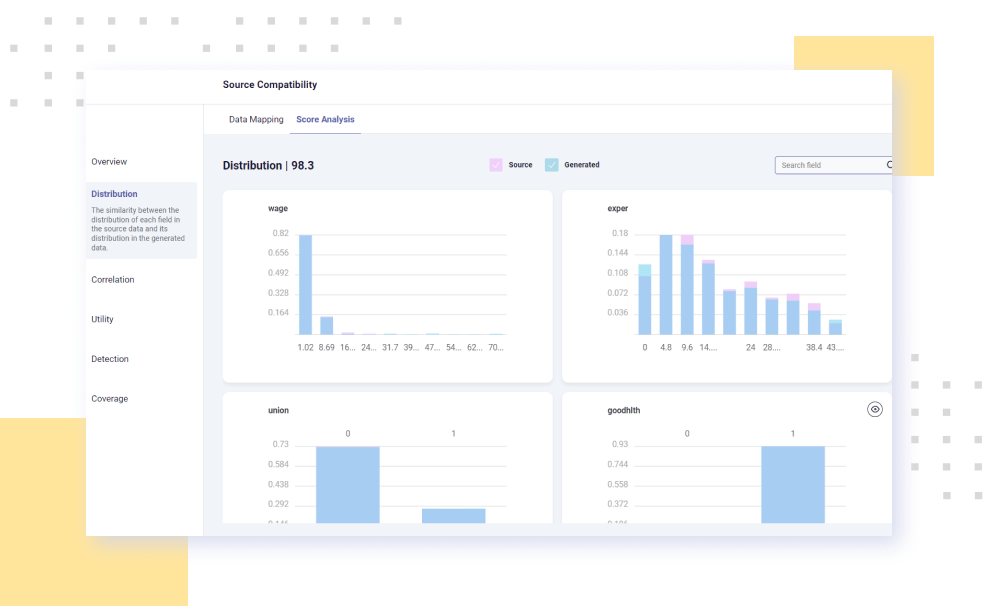
Datomize’s AI-powered, generative models create superior synthetic replicas by extracting the behavior from your existing data. Advanced augmentation capabilities enable limitless resizing of your data, while dynamic validation tools visualize the similarity between original and replicated data sets.
Recharge your data and train high performing models
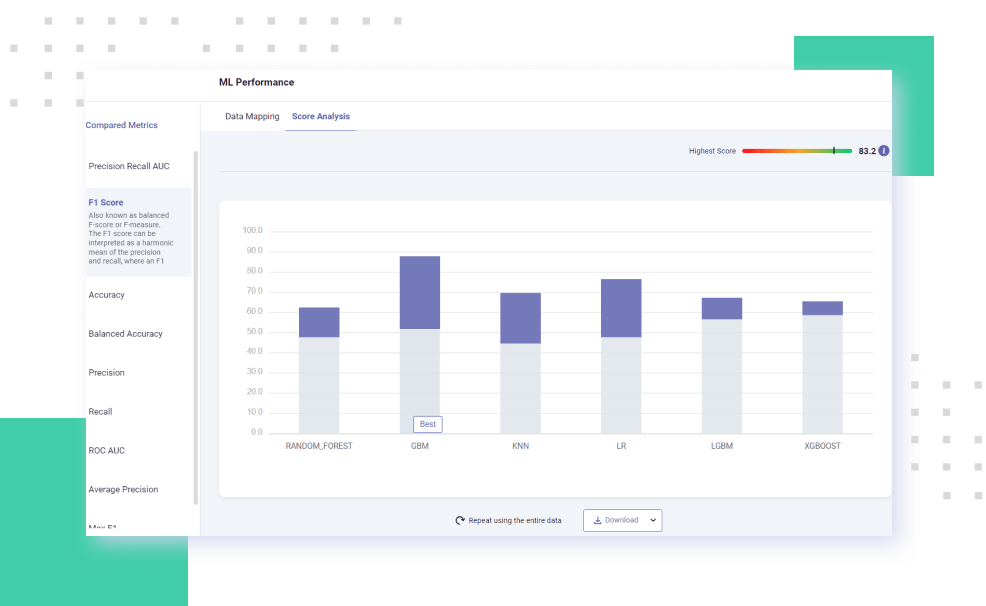
Datomize’s data-centric approach to machine learning, addresses the three primary data constraints of training high-performing ML models - quantity, inconsistency, and balance. Easily boost your ML model accuracy with data of superior quality and variety.
Reinvent your data to simulate any scenario
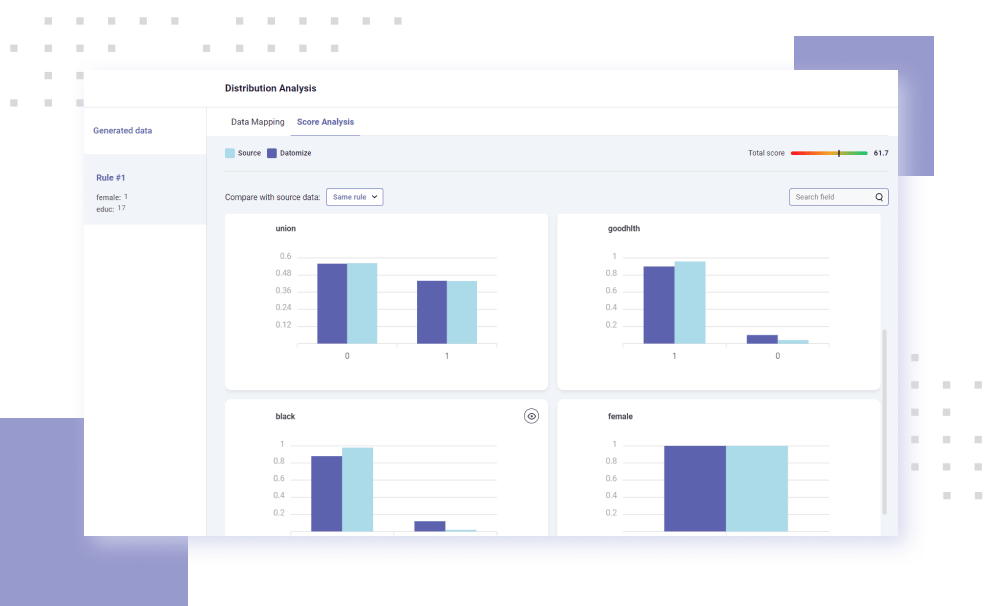
Datomize’s rules-based engine enables users to generate the exact analytical data set needed for any desired scenario. Together with the generative model trained on the source data, analysts and ML engineers can now generate data even for cases that lack previous examples.
Solution benefits
High performing ML Models
Develop and train the highest-performing ML models to extract superior insights by generating optimal training data with lower bias.

Predict outcomes for any scenario
Simulate future scenarios to fully understand user behavior, analyze trends, and predict outcomes across any set of conditions.

Overcome data bias and balance
Overcome insufficient representation, biased views, and ambiguity with data that is unbiased and balanced.

Integrate with existing data pipelines
Seamlessly integrate into existing analytical working environments and data or ML pipelines.

Confidence in data quality
Dynamic validation tools visualize the data quality resulting from continuous training of expert models.
Powerfully simple
With fully automated synthetic data generation and optional data mapping options, Datomize is powerful yet simple to use.

Complex data at scale
Synthesize or simulate massive data sets with 10s of millions of records, 100s fields per table and 100s of categories per field, including time-series and free text fields.

Rapid collaboration
Quickly provide partners with a synthetic version of sensitive data