Datomize provides a deep learning-based platform for generating synthetic data optimized to significantly improve ML model performance.
Efforts to improve ML performance based on benchmark datasets has been driving the progress of ML in recent years. While common practice is to improve the code, model, and/or algorithm, the secret sauce is hidden in the data. “The difference between good and bad (failed) deployments of ML-based systems depends primarily on the data rather than on fancy models”, Andrew Ng, Co-founder and head of Google Brain and former chief scientist at Baidu.
“Good” data for training ML models should have sufficient training instances (labeled data) to learn and generalize. The required number of samples is debated in many studies [1,2], and depends on a number of factors, including the complexity of the problem (the model’s parameters), the complexity of the learning ML algorithm, the ML task, and the input features. Some common rules of thumb for minimal data size (mainly for classic classifiers) consider a factor of the number of classes, and a factor of instances for each class (~1000). Another factor is the number of features, i.e. there should be tenfold more instances than features, and finally there should be at least tens of instances for each parameter.
All the above is true for non-complex linear models, however many complex problems require complex algorithms to reach sufficient performance. Non-linear ensembles and neural network models require far more data to learn complex relationship within the data, and are characterized by many parameters, and therefore are effective only with large datasets.
Despite the clear understanding that sufficient and “good” data is crucial for the performance of models, in many situations such data is not available. This situation is especially common in imbalanced scenarios such as buy events in e-commerce where the noise to signal ratio is low, or for medical data where a lot of data is available, but the desired events are too rare to learn from. The result of these types of scenarios very often leads to bias in predictions. For example, in the finance world models that predict signals for trading various financial assets are vulnerable to long bias due to rare, but critical short events. Training data should also cover extreme scenarios and present a wide variability of events to enable generalization over events of importance to the data owner.
One solution to the lack of “good” data is to obtain more data, specifically labeled data for training that follow desired properties. However, this “simple” solution is not feasible in many cases as labeling is a very costly and time consuming effort, and more data is not always readily available.
Other solutions may include transfer learning technology [3] which takes advantage of pre-trained models on data from similar related domains that can be adjusted to the current domain that lacks data. However, data from related source domains are not available in many cases. Data augmentation [4], a recently introduced technology targeting the “good” data problem, modifies existing instances to produce more augmented instances based on modifications of certain features of existing instances. The problem with this approach is that it retains the biases and faults of the original data instances. Augmentation algorithms are also still naïve, and struggle to demonstrate significant improvements to ML model performance [6].
Generating high quality synthetic data seems to be the best solution for this problem. The term synthetic data refers to data that is generated, not collected, and is created from scratch by a system based on the deep analysis of existing data. Synthetic data is scalable, can be tightly optimized for the problem at hand, is controlled and thus error-free, prevents lengthy data preparation tasks, and is rapidly generated, significantly reducing the time-to-market. Gartner recently estimated that by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
Existing synthetic data generation solutions [7,8,9] are most often optimized to generate data that closely resembles original data while preserving the privacy of the data, thus opting to keep the same properties of the data. These types of solutions are focused primarily on addressing the challenge of testing or analysis of proprietary data by third party services while complying with regulatory requirements. To evaluate these tools, models are trained using synthesized data, then compared to the their performance with the original data, with the goal of achieving comparable predictive performance.
Datomize’s revolutionary approach leverages synthetic data to dramatically improve the performance of ML models. Using deep learning technology, Datomize creates and trains a generative model on the fly, and then generates new data instances enabling control over variability, balance and bias. As a result, the evaluation of Datomize’s rich, augmented data set is successful only once the performance of trained models using the synthetic data outperforms the performance of models trained with the original datasets.
Datomize supports tabular and sequence data (time series), various data types, e.g. categorial, numeric, continuous, dates, etc., and is totally agnostic to the model at use. The Datomize platform requires minimal input from the user, is easy to deploy, and it automatically learns the dependencies within the data.
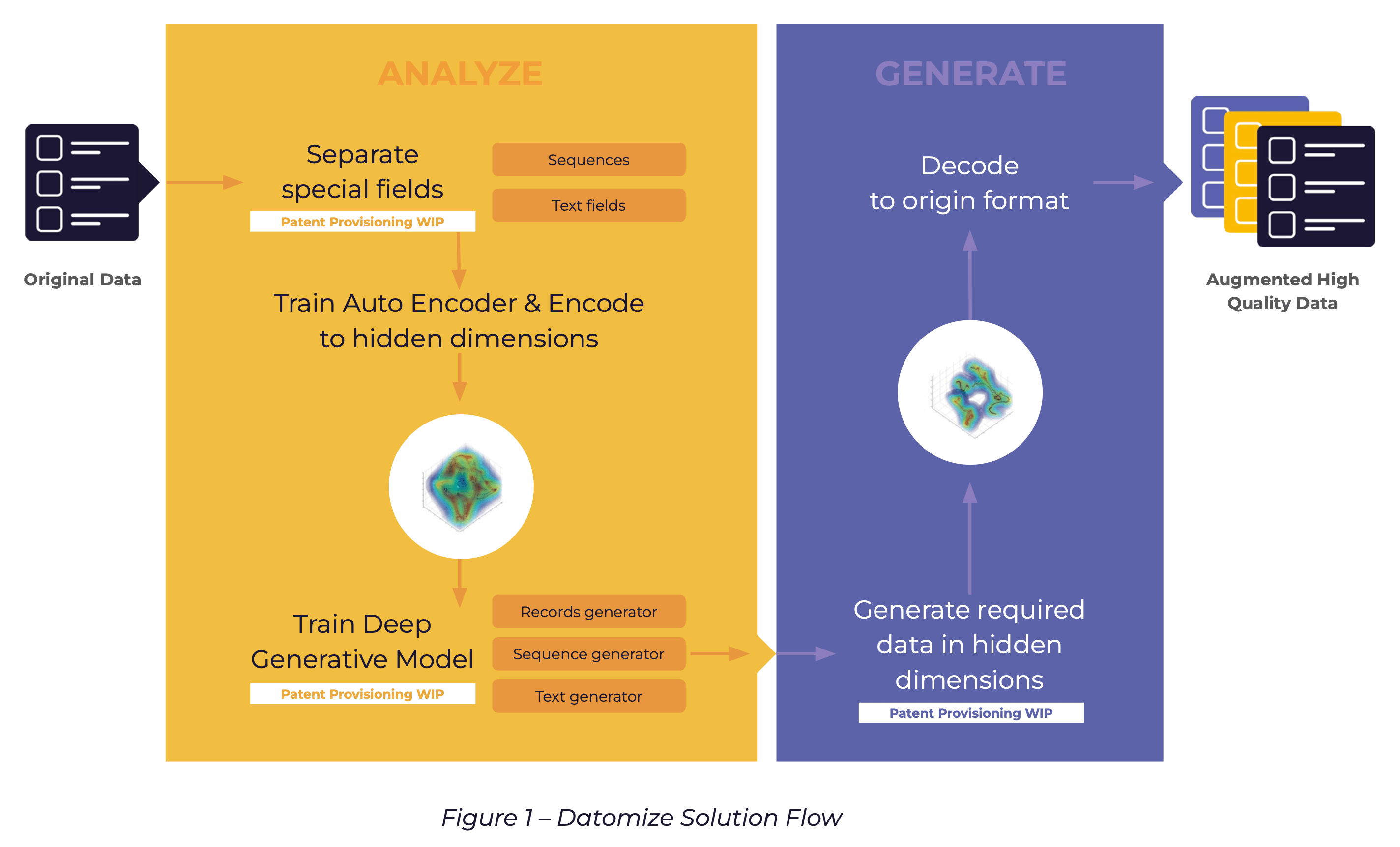
During the analysis phase Datomize imports the original data, automatically analyses the structure and dependencies of the data, and then applies autoencoders to encodes the data to latent representation. Datomize then creates and trains the deep generative model using the encoding results. During the generation phase, data is generated and decoded back to the original format.
References:
[1] Baum, E. B., & Haussler, D. (1989). What size net gives valid generalization?. Neural computation, 1(1), 151-160.
[2] Balki, I., Amirabadi, A., Levman, J., Martel, A. L., Emersic, Z., Meden, B., … & Tyrrell, P. N. (2019). Sample-size determination methodologies for machine learning in medical imaging research: a systematic review. Canadian Association of Radiologists Journal, 70(4), 344-353.for a review of studies
[3] F. Zhuang et al., “A Comprehensive Survey on Transfer Learning,” in Proceedings of the IEEE, vol. 109, no. 1, pp. 43-76, Jan. 2021, doi: 10.1109/JPROC.2020.3004555.
[4] Connor Shorten and Taghi M Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of Big Data, 6(1):60, 2019
[5] Xu, Y., Noy, A., Lin, M., Qian, Q., Li, H., & Jin, R. (2020). WeMix: How to Better Utilize Data Augmentation. arXiv preprint arXiv:2010.01267.
[6] Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. Understanding and mitigating the tradeoff between robustness and accuracy. arXiv preprint arXiv:2002.10716, 2020.
[7] Assefa, S. A., Dervovic, D., Mahfouz, M., Tillman, R. E., Reddy, P., & Veloso, M. (2020, October). Generating synthetic data in finance: opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance (pp. 1-8).
[8] Abay, N. C., Zhou, Y., Kantarcioglu, M., Thuraisingham, B., & Sweeney, L. (2018, September). Privacy preserving synthetic data release using deep learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (pp. 510-526). Springer, Cham.
[9] Hittmeir, M., Ekelhart, A., & Mayer, R. (2019, August). On the utility of synthetic data: An empirical evaluation on machine learning tasks. In Proceedings of the 14th International Conference on Availability, Reliability and Security (pp. 1-6).
