
Introduction
Over the last two decades the dominant approach to AI has been model-centric. The approach was based on developing a model that was good enough to deal with the given data gaps by keeping the data constant while iteratively improving the model until it performed the best. Over the course of 2021 we witnessed a data-centric approach to optimizing AI models emerge[1]. Given the maturity of the model-centric approach, state of the art open-source models for most of the tasks organizations are struggling to solve have been developed, and in order to improve performance it is no longer about trying to optimize the model but rather to optimize the data being used to train the model. This data-centric approach is based on keeping the model or code constant and iteratively improving the quality of the data.
In this document we present a benchmark that demonstrates the power of Datomize’s data-centric approach to enhancing ML model performance. The benchmark focuses on imbalanced binary prediction tasks with small to medium dataset sizes (hundreds to tens of thousands of records).
In binary imbalanced tasks such as defect prediction, fraud detection, or disease detection, the data is composed of two classes: the majority class and the minority class. The minority class is a rare case, which is also the most interesting case as, it is normally very important to detect the minority class correctly in order to ensure that as many frauds, defects, or sick patients as possible are identified, even at the price of false alarms. However, it is usually harder to predict the minority class as it is not represented well enough in the source data. Balancing techniques are a common approach for dealing with imbalanced data, either by under sampling the majority class, oversampling the minority class, or both.
Datomize’s enhanced ML capabilities optimize the training data by wisely selecting, repairing, and augmenting the source data. It can therefore be rapidly used to enhance small and imbalanced datasets that yield more accurate prediction models. To demonstrate the superiority of Datomize’s generative model, we ran a set of tests and compared its performance to five (5) additional state of the art, open-source generative models (see Table 1).
The Benchmark Workflow
We ran Datomize’s data enhancement process on 40 binary prediction tasks. See Table 1 below.
The enhancement process, utilizing Datomize’s generative models, automatically augments and balances the data while iterating to optimize the performance of various evaluation metrics. As most of the datasets are imbalanced, we mainly focused on F1 score, Recall, and Precision as evaluation metrics. See Table 2 below.

In an imbalanced task the recall measure becomes an important performance metric as it is normally very important to detect the minority class correctly, even at the price of false alarms. Precision, on the other hand, measures how accurate an average forecast is. There is obviously a tradeoff between recall and precision, as 100% recall (referring to all patients as sick, for example) yields poor precision. To best handle this tradeoff, we use the F1 score as our core evaluation metric, which is a combination (an harmonic mean) of the previous two.
Datomize’s evaluation setup is based on five (5) fold cross-validation. This means that we split the source data randomly into five portions, and repeat the process 5 times, each with a different portion used as a test set for evaluating the results achieved, based on a process fed with all other portions of the data as the training data. We then report the average values of the evaluation results obtained in the five (5) executions of the model. A single process includes:
- Training a generative model based on the training data and utilizing it to generate optimized training data
- Using five (5) different algorithms to:
- Train model A with the original training data
- Train model B with the optimized (Datomize’s) training data
- Evaluating models A and B using the test data with the 3 evaluation metrics (see Table 2), and calculating the difference between their performance according to each of the metrics
- Calculating the average difference in performance according to all five (5) algorithms for each of the three (3) metrics.
Results
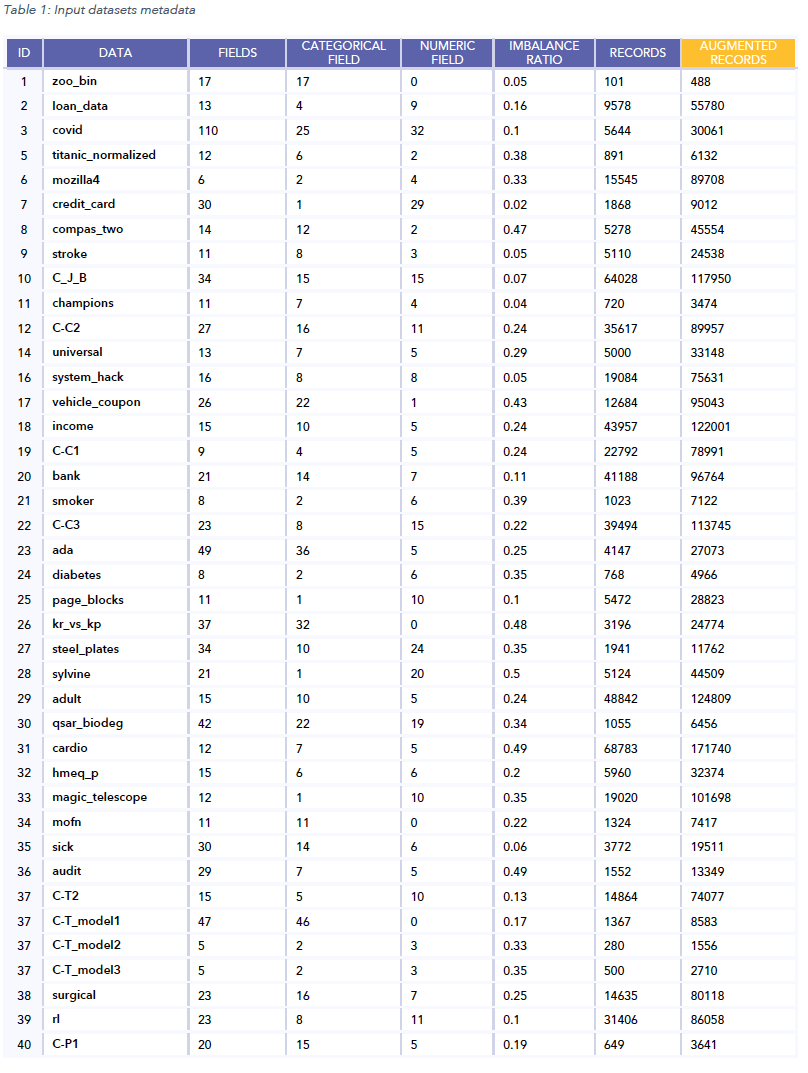
Figure 1 presents a summary of the achieved results. Defining an improvement as at least 0.5% increase in a given metric, we see that the Datomize enhanced ML process improved the F1 score for 70% (28) of the datasets, with an average increase size of 8%. A recall improvement was achieved for 75% (30) of the datasets, and in 12.5% (4) of the datasets a precision increase was achieved as well.
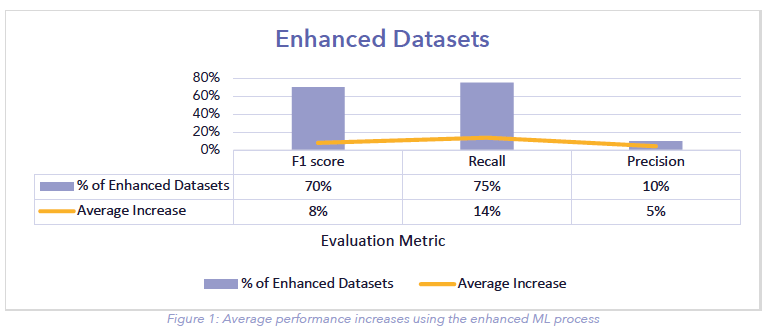
The detailed results per dataset are described in Figure 2:
Conclusions and Future Work
- The benchmark demonstrated how Datomizesignificantly enhances ML model performance using a data-centric approach.
- Datomize increased the F1 score for 70% of the 40 input datasets with an average increase of 8%.
- We are currently working on further improving the optimization process, as well as adjusting it to multi-value categorical and numeric targets as well as bigger datasets with up to 1.5M records.
References:
[1] https://www.forbes.com/sites/gilpress/2021/06/16/andrew-ng-launches-a-campaign-for-data-centric-ai/?sh=101f9d9674f5
