Turn the Data You Have into the Data You Need
September 7, 2023
The Power and Limitations of Data
Data is a powerful resource today. In addition to its role in fueling the AI and machine learning revolution underway, data is used as a simulation tool in diverse scenarios, including product development, decision making, what-if analysis, and forecasting, where it provides valuable insights and understanding, inaccessible by traditional means of analysis.
While in today’s big data era it often seems as though organizations are swimming in data, the reality is that the high-quality data a given entity needs is often limited, out of reach, or extremely expensive to collect. Without the critical data, organizations’ ability to simulate new, unseen scenarios and intelligently play out different courses of action and examine their consequences is compromised.
The inconsistent quality and limited availability of data threaten to slow the pace of the machine learning revolution, as the models that machine learning relies on to make its decisions are only as good as the data used to train them. Machine learning models use this input data to learn, and the knowledge they acquire underlies their decisions, predictions, and classifications, and the insights they provide. A lack of relevant training data limits machine learning models’ accuracy and the quality of their output, which in turn limits their widespread adoption and ability to realize their potential.
Both the quality and representativeness of the available data are important. Analysis capabilities suffer when a segment of the population is excluded from the data, compromising decision making and resulting in a situation in which the decisions derived from a model trained on incomplete data are met with skepticism. Without adequate data, analysts’ hands are often tied as they struggle to collect data for the missing demographics, a process which can be costly and time consuming.
In the world of machine learning, a model may demonstrate outstanding performance on data that is similar to the training data but be unable to maintain high performance when faced with new and dissimilar data. Data scientists strive to create generic machine learning models that perform well on new, previously unseen data. Significant effort is made to improve the models and ensure that they are equipped to handle uncertainties, variations, and shifts in data distribution, and demonstrate high performance across a wide spectrum of observations.
Data Bias
When a data set fails to represent the entire population, data bias occurs. In a world driven by data, this can have serious consequences, particularly when machine learning models are deployed in sensitive domains like healthcare and criminal justice, where a model’s decision can have great impact on people’s lives; in some cases, the omission of data segments can contribute to discrimination and inequality. Data bias can also have a dramatic effect on machine learning model performance. Even a model that generalizes well can suffer if the data it was trained on was insufficiently representative; in the training process, the model may not learn enough about the unique patterns and characteristics associated with the missing segment. As a result, when faced with instances from the underrepresented or missing segment during deployment, the model’s performance is likely to be limited. And in the analysis and decision-making process scenarios, data bias results in faulty decision making, incorrect conclusions, and everything else that follows when the incorrect course of action is taken based on these conclusions and decisions.
The dynamic nature of data can also cause bias. Global pandemics, economic downturns, and regulatory changes are among the many events that can lead to significant shifts in fields as diverse as healthcare, economics, and even online shopping. Given data’s dynamic nature, models that rely on historical data, like those used in medical recommendation systems to predict patient treatment or those used by banks to predict loan repayment behavior, are in jeopardy of yielding predictions that are either incorrect or irrelevant to new circumstances. The potential impact of such events underscores the importance of models’ that can accurately make predictions on previously unseen data; the relevance of models without this capability diminishes in evolving circumstances.
The effect of bias stemming from the underrepresentation of some data segments on machine learning model performance has caused data scientists to dedicate considerable time and effort to minimizing data bias. But data bias is not just preoccupying data scientists—governments and organizations around the world have become increasingly concerned about the effect of data bias on society. This has resulted in increased data regulation, making it essential to ensure that machine learning models remain unbiased.
One way of minimizing data bias is to train machine learning models on representative data sets that reflect most segments of the population. This can be done by creating new data and enhancing the training data with the new data. The creation of new segments of data requires the expertise of individuals familiar with the data and its limitations. For example, a bank analyst who knows that young couples with children are underrepresented in the data might recommend collecting additional data representing this demographic, with the aim of increasing the model’s understanding and improving its performance for that segment. This solution poses several challenges, as it is costly and time consuming, and its applicability may be limited in certain cases.
Datomize’s Reinvent Tool
These disadvantages are not seen when advanced generative AI techniques are used to simulate data. And this is why we developed our Reinvent tool, a state-of-the-art data augmentation and simulation solution.
Datomize’s Reinvent tool uses generative AI (specifically, deep neural networks). As such, it learns from the patterns in the training data to generate new data. Reinvent was designed to generate synthetic data (even missing data segments) and enable the exploration of new data scenarios. With this tool you can generate more instances for selected scenarios or simulate new scenarios to overcome the problem of data bias.
Reinvent’s architecture combines a variational autoencoder (VAE) and conditional generative adversarial network (GAN), in which user-defined rules play a role in the data generation process. For instance, if female patients that smoke are underrepresented in a data set, Reinvent’s generative model uses the training data to synthesize new data based on these criteria: (1) gender – female, and (2) smoking – true. In this case, the synthetic data for the underrepresented segment is generated and added to the training data, allowing the model to learn from a more diverse range of examples.
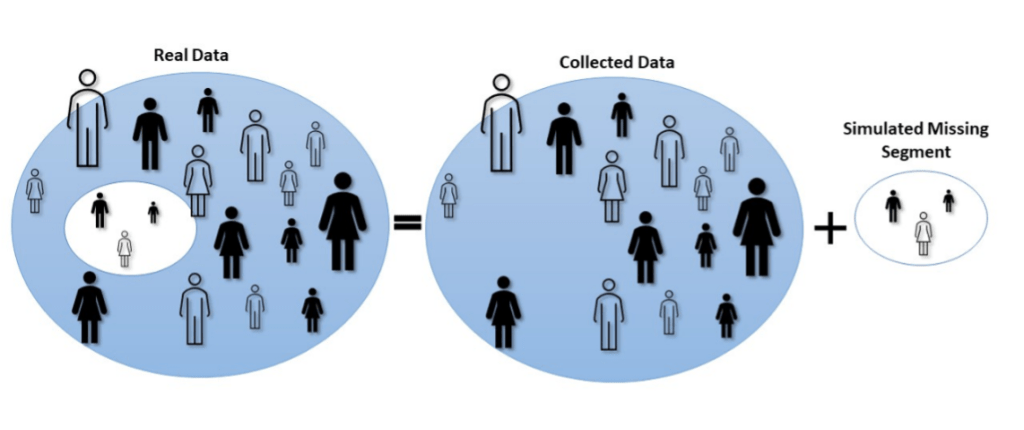
To demonstrate Reinvent’s effectiveness, we considered three scenarios in which a segment of the data was missing and used Reinvent to synthesize the missing segment; the synthesized segment was then used to augment the training data. For example, in one scenario, we extracted all high-income women over the age of 55 from the data and split the remaining data into training and test sets. Reinvent was used to synthesize the data that was removed, relying on just the training data to do so.
To examine the impact of the synthesized data on model performance, we created two models: one trained only on the training data and the other trained on the training data augmented by the synthesized data segment. The models’ performance was evaluated on the binary classification task of determining whether a person makes over $50K a year, with the following test sets: (1) the original test set, (2) a test set consisting of the original extracted data segment, and (3) a combination of 1 and 2. We found that the model trained on the Reinvent-simulated data outperformed the model that was trained on just the original data when the test set contained records from the extracted data segment (test sets 2 and 3 above).
Our evaluation and results, which are described in greater detail below, demonstrate Reinvent’s ability to synthesize high-quality data and the benefits of augmenting the training data with the Reinvent-simulated data. Our evaluation particularly highlights Reinvent’s ability to contribute to machine learning models’ performance and accuracy when faced with new, unobserved scenarios (as assessed using test sets 2 and 3). The high quality of the Reinvent-simulated data was also showcased in our evaluation, as the models performed better when trained on the synthetic data.
By helping create accurate and representative data sets, Reinvent can contribute to improved machine learning model performance and serve as a highly effective simulation tool, enabling organizations to explore a wide range of scenarios in product development, decision making, what-if analysis, forecasting, and more. In this way, Reinvent unleashes the potential of data, which is among an organization’s greatest assets.
Recent developments in generative AI leveraged by Datomize’s Reinvent tool enable organizations to generate the required data and address missing data scenarios. With Reinvent, high-quality synthetic data can be yours in no time.
Start practicing generative AI with Datomize (https://www.datomize.com/contact/).
More Details on Our Evaluation and Findings
We now provide a more detailed description of our evaluation of Reinvent’s effectiveness and share our findings.
In our evaluation, we used the Adult Census Income data set from the UCI repository. It contains the records of 48,842 individuals and was created for the binary classification task of predicting high-income individuals (whose income is over $50K per year).
We simulated three scenarios by extracting the following specific, predefined data segments from the data:
- High-income women over the age of 55 (203 records)
- High-income men under the age of 30 (566 records)
- High-income, non-white individuals with less than 10 years of education (250 records)
For each scenario, we split the remaining data into training (80%) and test sets (20%) using a stratified approach, meaning that the training and test sets did not include the extracted data segment. For example, the high-income women over the age of 55 segment was extracted using rule-based filtering with the following criteria: gender – female, age – over 55, and income – over $50K annually. This filtering yielded a subset of 203 records that met the criteria (this subset was used later for model testing). The remaining 48,639 records were split into training and test sets. Then, we used Reinvent to synthesize the missing data segment. To do this, we provided the training set, along with the criteria used to extract a given segment, and asked Reinvent to generate 1,000 records that met the same criteria.
We then trained three machine learning classifiers (an: XGB classifier, LGBM classifier, and random forest (RF) classifier), which were used to perform the binary classification task of determining whether a person makes over $50K a year.
For each scenario and classifier combination examined, we trained two models:
- A model trained on the original training data
- A model trained on the augmented training data (the original training data plus the 1,000 synthesized records produced by Reinvent)
Because the data was imbalanced (high income individuals comprised 24% of the data set), we used the F1 score to assess model performance on the following test sets:
- Original test set (excluding the extracted segment) – The original test set, which contains no records from the extracted segment. This allows us to evaluate model performance on previously unseen data among familiar data.
- Extracted segment – The records of the extracted segment. This is used to evaluate model performance on previously unseen data representing unfamiliar segments of the population.
- Combined data – The original test set, plus the records of the original extracted segment. This is used to assess the model’s ability to manage both new, previously unobserved data that is aligned with the training data set, and new, unfamiliar segments of the population that vary from the training data in some respect.
The results of our evaluation are presented in the table below. As can be seen, when the synthesized segment produced by Reinvent was used in model training (serving as a replacement for the extracted segment), model performance improved when the model was faced with unfamiliar scenarios (as assessed using the test sets containing records from the extracted segments). This finding highlights Reinvent’s ability to provide synthesized data that can be used to augment the training data and contribute to machine learning models’ accuracy and relevance when faced with new, unobserved scenarios. This finding also points to the quality of the Reinvent-simulated data and Reinvent’s ability to effectively simulate missing parts of the data.
For example, in the high-income men under the age of 30 scenario, the results presented in the table show that when the training set lacks data for this group, the trained XGBoost model achieved an F1 score of 0.66 on the combined data test set but poorly classified the records from the extracted segments (high-income young men), obtaining a low F1 score of 0.242 in that case. However, when the training set included the Reinvent-simulated records of high-income men under 30, the model achieved an F1 score of 0.71 on the combined data and performed even better on the test set containing just the extracted segment, on which it achieved an F1 score of 0.767 (the results on this test set for each scenario appear in bold in the table). These high scores demonstrate the quality of the Reinvent-simulated data and its contribution to improved performance.
We note, however, that the use of the synthesized segment caused a decrease in model performance on the known, familiar data, because the generalizability of the model increased. In this case, with the original test set, models trained on the original training data obtained higher F1 scores than models that were trained on the augmented training data.
It is well known that there is a trade-off between a model’s performance and its ability to generalize; the objective of creating a more generalizable model may come at the cost of a reduction in the model’s score. This trade-off, however, is offset by increased model robustness and the ability to effectively handle a broader range of observations that may not be precisely aligned with the collected data (like the extracted segments).
A Comparison of Model Performance (F1 score)
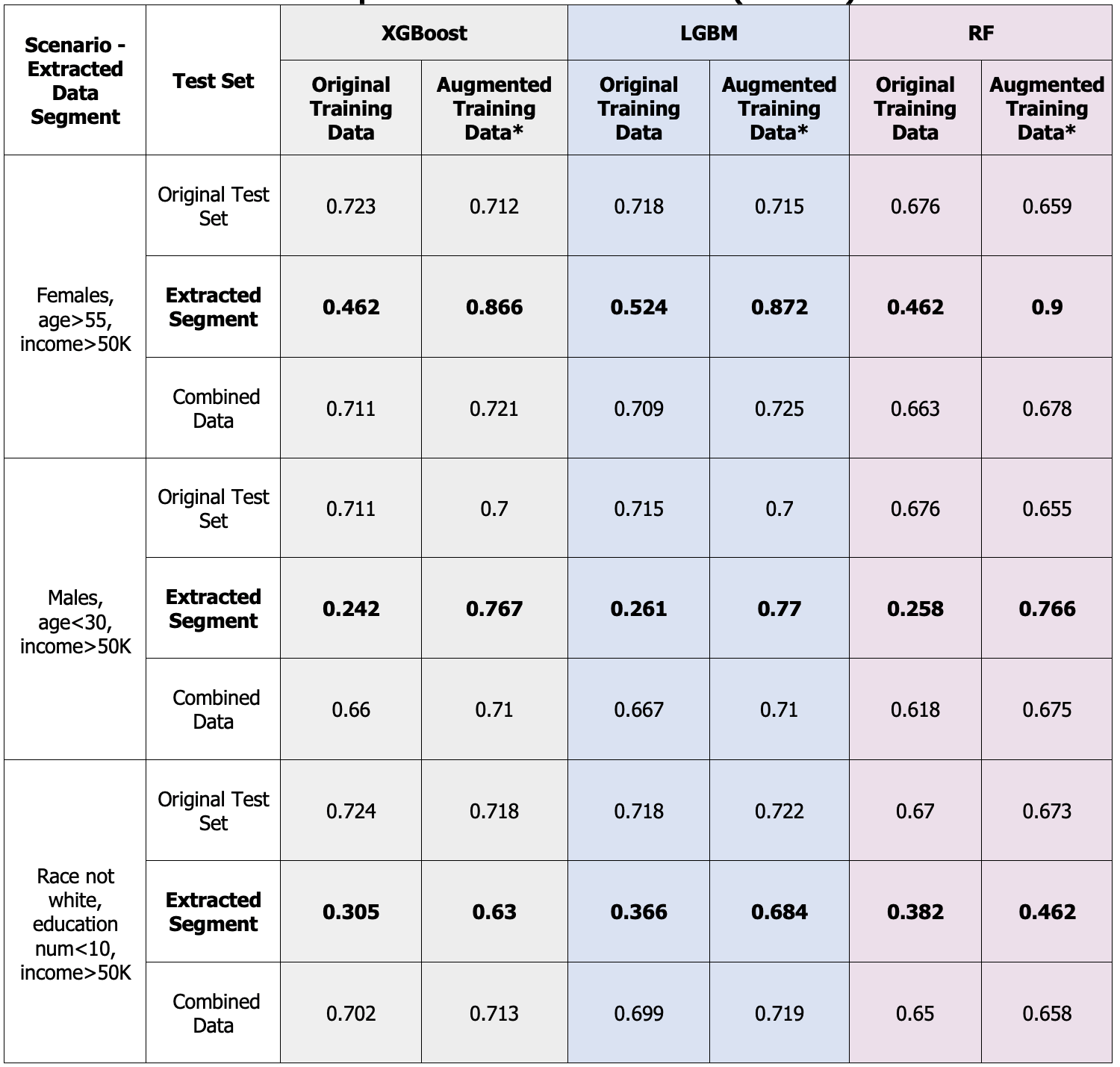
*The original training data + the synthesized segment
Our evaluation and results demonstrate Reinvent’s outstanding capabilities as a simulation tool and its ability to improve machine learning model performance, but we encourage you to schedule a demo to see how Datomize’s Reinvent tool can help you unleash the power of your data.
Start practicing generative AI with Datomize (https://www.datomize.com/contact/).
