The use of artificial intelligence (AI) is increasing in so many aspects of our lives—health, social services, and criminal justice to name a few.
AI techniques must be implemented responsibly as they mature and become more widely used to ensure that no ethical improprieties arise. Although with time AI is likely to become more regulated, organizations already have a duty to protect individuals’ privacy and guarantee that the data in the models they use is fair and unbiased, eliminating any risk of excluding, marginalizing, or exploiting particular communities.
Significant effort is being made to detect and address these concerns at the model level, but many of the risks are inherent in the data itself, since the AI model makes decisions based on behaviors extracted from the given training data. The capabilities of Datomize’s augmented data platform can help mitigate these risks at the root—at the data level, helping to ensure ethical AI implementation.
Data Privacy
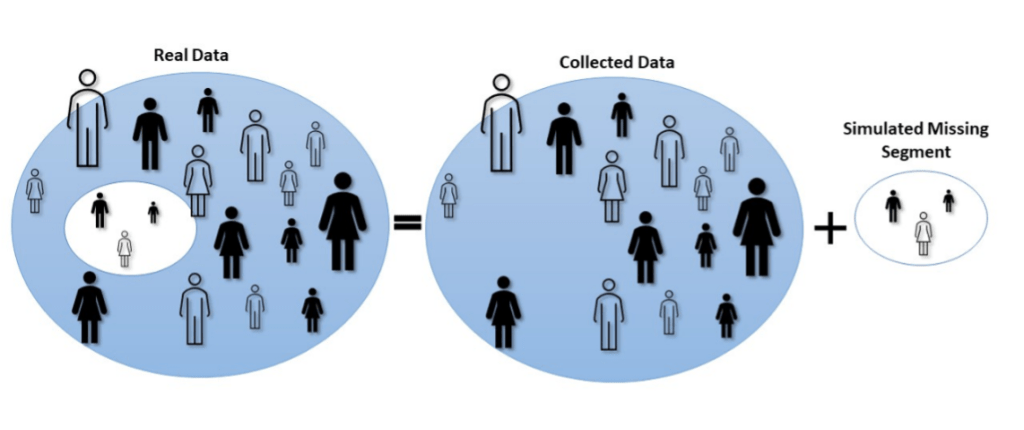
To protect individuals’ privacy, the data used to train the machine learning (ML) models must not expose any identifiable details about the individuals whose data is being analyzed. Various techniques are available for protecting this type of personal information, including encryption, anonymization, and the use of synthetic data. Synthetic data is the safest option since you don’t have to trust an encryption key holder or worry that some non-anonymized fields might eventually be combined with external data to identify individuals. Synthetic data is composed of new individual records, generated from random noise, which cannot be traced back to an actual individual.
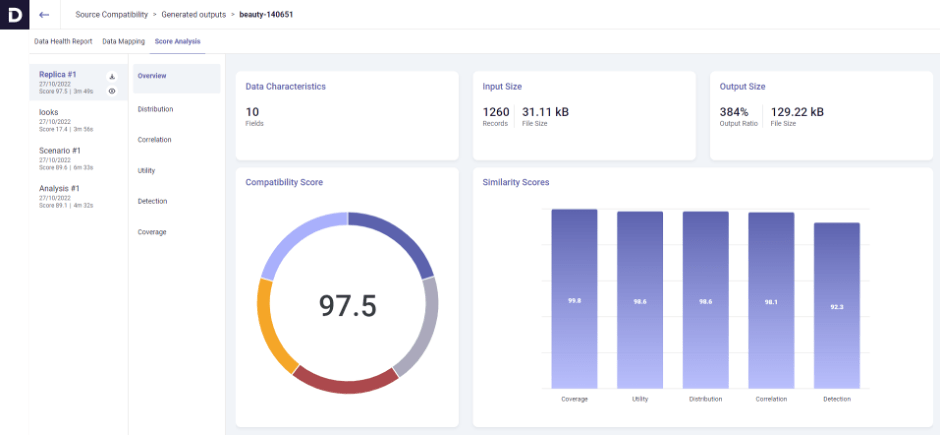
Datomize’s solution makes it extremely easy to convert datasets into safe synthetic replicas. Our dynamic dashboard allows you to analyze the degree of similarity between the generated replica and the source data.
Data Bias and Fairness
AI fairness addresses the need for models that perform similarly on various populations. An unfair model can result from training data that does not adequately represent the population for which predictions will be made. For example, when the training data lacks representation of Black women, a model trained on this data will perform poorly for that population. Various metrics can be used to detect bias after the model has been trained, but most of the bias is rooted in the training data. Alternatively, bias detection and correction can be applied to the data before training, to prevent biased models and guarantee fair AI.
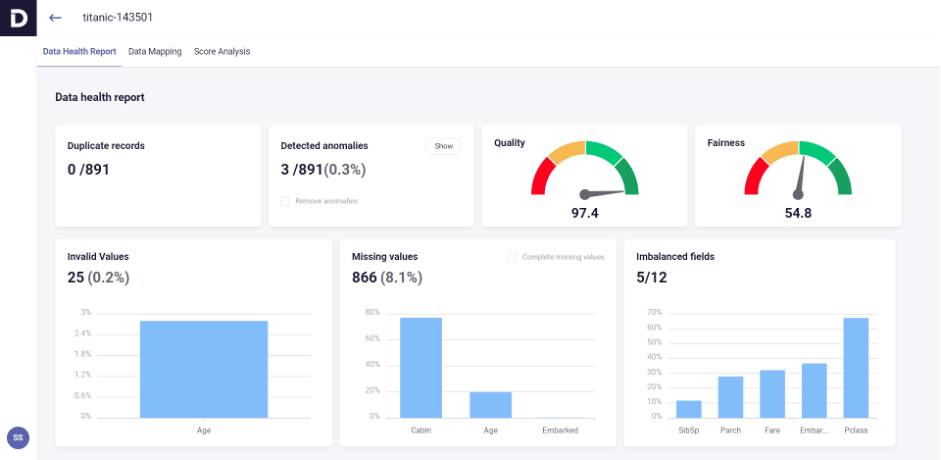
Datomize recently took its first steps in this direction by providing the capability to detect and measure bias stemming from imbalanced fields in a dataset. The resulting fairness score is presented in the data health report, as shown in the figure below:
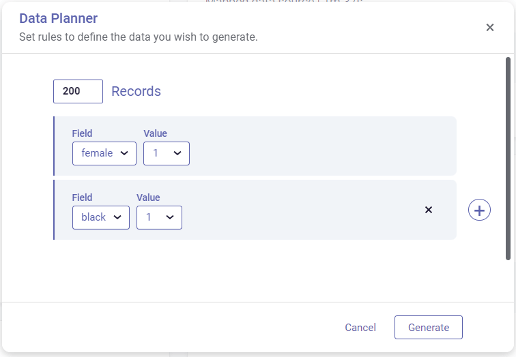
Users can dynamically explore imbalanced fields (as shown in the figure above) and correct them by adding synthetic data to address existing data gaps by using Datomize’s rule engine generator, as described below: